Loss Functions in Neural Networks
Overview
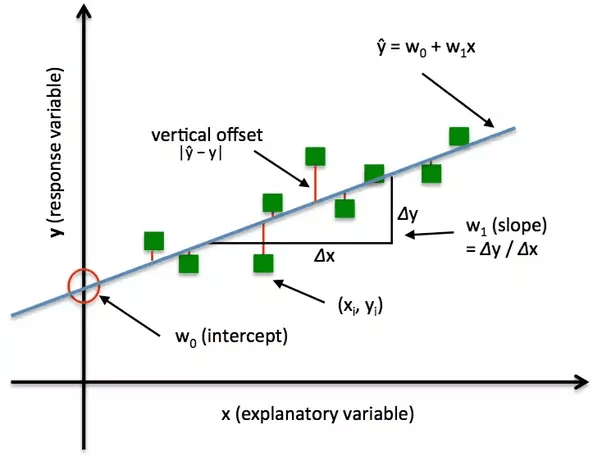
Loss functions, also known as cost functions or objective functions, are critical components in the training of neural networks. They measure the difference between the model’s predictions and the actual target values, providing a way to evaluate the performance of the model. The goal of training a neural network is to minimize the loss function, thereby improving the model’s accuracy.
For loss functions to be effective in any way, normalization of the data is required. If there is a difference in scaling for competiting features of a dataset, then some will overpower the others in their percieved value
Purpose of Loss Functions
-
Quantifying Error
- Loss functions provide a numerical value that quantifies the error between the predicted output and the actual target. This value guides the optimization process.
-
Guiding Optimization
- During training, the model adjusts its weights and biases based on the gradient of the loss function. The direction and magnitude of weight updates are determined by how the loss changes with respect to each parameter. This process is typically done using algorithms like gradient descent.
-
Comparing Models
- Loss functions allow for the comparison of different models or model configurations. A lower loss indicates a model that is performing better, making it easier to select the best model architecture.
Types of Loss Functions
1. Mean Squared Error (MSE)
-
Formula:
MSE = (1/n) * Σ (yᵢ - ŷᵢ)²where
yᵢis the actual value,ŷᵢis the predicted value, andnis the number of samples. -
Use Case:
- Commonly used for regression tasks where the goal is to predict a continuous value.
-
Characteristics:
- Penalizes larger errors more heavily due to the squaring of differences.
- Sensitive to outliers, as large errors can disproportionately affect the loss.
2. Cross-Entropy Loss
-
Binary Cross-Entropy:
L = -[y log(ŷ) + (1 - y) log(1 - ŷ)]where
yis the actual label (0 or 1), andŷis the predicted probability. -
Categorical Cross-Entropy:
L = -Σ yᵢ log(ŷᵢ)for multi-class classification, where
yᵢis the one-hot encoded true label, andŷᵢis the predicted probability for classi. -
Use Case:
- Widely used in classification tasks, both binary and multi-class.
-
Characteristics:
- Measures the difference between two probability distributions (the true labels and the predicted probabilities).
- Encourages the model to output probabilities close to 0 or 1, reducing uncertainty in predictions.
3. Hinge Loss
-
Formula:
L = max(0, 1 - yᵢ * ŷᵢ)where
yᵢis the true label (either -1 or 1), andŷᵢis the predicted output. -
Use Case:
- Commonly used in Support Vector Machines (SVM) for binary classification tasks.
-
Characteristics:
- Encourages a large margin between classes, pushing the decision boundary away from data points.
- The loss is only incurred if the data point is within the margin or misclassified.
4. Huber Loss
- Formula:
- Combines MSE and Mean Absolute Error (MAE). For small errors, it behaves like MSE, and for larger errors, it behaves like MAE.
- Use Case:
- Useful in regression tasks where the dataset contains outliers.
- Characteristics:
- Less sensitive to outliers than MSE.
- Provides a balance between the robustness of MAE and the sensitivity of MSE.
Choosing a Loss Function
The choice of a loss function depends on the type of problem you’re solving:
- Regression Tasks: Mean Squared Error (MSE) is commonly used, but Huber Loss is an alternative when dealing with outliers.
- Classification Tasks: Cross-Entropy Loss is the standard for both binary and multi-class classification.
- Support Vector Machines: Hinge Loss is used to create a decision boundary with a margin.
Summary
Loss functions are essential for training neural networks as they provide the objective that the network seeks to minimize. By carefully selecting and optimizing based on the appropriate loss function, you can guide your model towards better performance, whether it’s in regression, classification, or other types of predictive tasks.