Activation Functions in Neural Networks
Overview
Activation functions are essential components of neural networks that determine whether a neuron should be activated or not. They introduce non-linearity into the model, enabling it to learn complex patterns and relationships in data. Without activation functions, the neural network would behave like a linear model, regardless of its depth.
Types of Activation Functions
-
Sigmoid Function
- Formula:
σ(x) = 1 / (1 + e^(-x)) - Range: (0, 1)
- Characteristics:
- Squashes input values to a range between 0 and 1.
- Commonly used in the output layer for binary classification problems.
- The gradient diminishes as the absolute value of input increases, which can slow down learning.
- Formula:
-
Tanh (Hyperbolic Tangent)
- Formula:
tanh(x) = (e^x - e^(-x)) / (e^x + e^(-x)) - Range: (-1, 1)
- Characteristics:
- Outputs values between -1 and 1, making it zero-centered.
- Typically used in hidden layers of neural networks.
- Like the sigmoid, it can suffer from vanishing gradients, especially with deeper networks.
- Formula:
-
ReLU (Rectified Linear Unit)
- Formula:
f(x) = max(0, x) - Range: [0, ∞)
- Characteristics:
- Introduces non-linearity by outputting the input directly if it’s positive, otherwise, it outputs zero.
- Efficient and easy to compute.
- Helps alleviate the vanishing gradient problem.
- Can suffer from the “dying ReLU” problem, where neurons can get stuck in a state of always outputting 0.
- Formula:
-
Leaky ReLU
- Formula:
f(x) = x if x > 0, otherwise αx (where α is a small constant) - Range: (-∞, ∞)
- Characteristics:
- A variation of ReLU that allows a small, non-zero gradient when the input is negative.
- Helps mitigate the dying ReLU problem.
- Formula:
-
Softmax
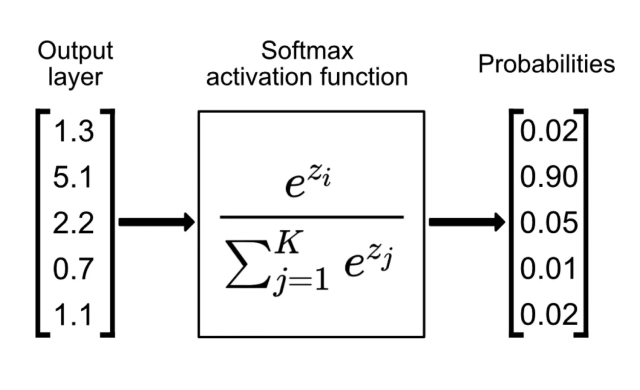
- Formula:
σ(z_i) = e^(z_i) / Σ(e^(z_j))for each classi - Range: (0, 1)
- Characteristics:
- Converts a vector of raw scores (logits) into probabilities.
- The sum of the output probabilities is 1.
- Commonly used in the output layer of multi-class classification problems.
- Formula:
Choosing an Activation Function
The choice of activation function depends on the specific task and architecture of the neural network:
- Sigmoid and Tanh are more suitable for shallow networks and binary classification tasks.
- ReLU and its variants (like Leaky ReLU) are generally preferred in hidden layers of deep networks due to their efficiency and ability to mitigate vanishing gradients.
- Softmax is typically used in the output layer for multi-class classification tasks.
In my project, Modeling XOR Gate, I used ReLu for the hidden layer, but sigmoid for the output layer.
Practical Considerations
- Vanishing Gradient Problem: Functions like Sigmoid and Tanh can cause gradients to shrink significantly, slowing down the learning process. ReLU and its variants are often used to address this issue.
- Exploding Gradient Problem: While not as directly related to the choice of activation function, this issue can occur in deep networks. Techniques like gradient clipping or normalization can help.
- Dying ReLU Problem: Some neurons might “die” and only output zero. Leaky ReLU is a common solution to this problem.
Conclusion
Activation functions play a critical role in the performance and training of neural networks. Understanding their properties and choosing the right one for your specific use case can significantly impact the effectiveness of your models.