DARS
CS2210 Final Project
Date: 9/27/2024
Team: CASE
Ewan Pedersen - Project Lead

while this isnt what ours will look like, it sure gave us inspiration
Table Of Contents
Introduction
DARS is a advanced dormitory management system that, thanks to the power of transformer based language models, will be able to interpret human natural language and route that to a proper room management action. On the surface, DARS will resemble the appearance of TARS from interstellar, and will share many traits of his personality. However, unlike other similar projects, DARS will be able to understand and interpret natural language, and will be able to perform complex actions such as room assignments, room management, and more.
By meeting these claims, DARS will not only be able to serve as an entertaining personality thanks to his open source model architecture, but also to serve as a powerfull interface for home automation. But the language model is not the only thing that will make DARS what he is.
DARS will also be running 2 other neural models locally, one for speech recodnition, and one for speech synthesis. This will be so that DARS will be able to understand the speaker without issue, but also mimic the well known voice of TARS.
In addition, DARS will present a simple and expansable interface so that devices can easily be added to the “network” of control. Wireless microcontrollers will be used to control devices, and the language model will be able to interface with them to control them.
Definitions, Acronyms, and Abbreviations
DARS: We chose the name DARS for a few reasons. Firstly, it is a play on the name TARS, the robot from interstellar. Secondly, it is an acronym for Dormitory Automated Residential System. This is because DARS will be able to manage dormitories, and provide room service to the residents.
Ollama: Ollama is the open source language model that we will be fine tuning and trainning to be able to understand and interpret human natural language like TARS would. Ollama comes in several variations, but we will be using the 8B parameter model for our project due to the hardware limitations of the rasberry pi 5.
Project Detail
This project will involve undertaking the difficult task of training large language models. This is going to be difficult as, even in the smallest of these models, such as the 8B parameter model, the model will be too large to fit on the raspberry pi 5. This will require us to train the model on a more powerful machine, and then convert the model to a smaller size that will fit on the raspberry pi 5.
For this, we are planning to rent an Nvidia A100 for a few days to train the model. This will be expensive, but it is necessary for the project to be a success.
Full System Diagram
This system is going to be much more complicated than we initially thought, as we have to route human natural language through quite a bit of processes before it is turned into a desirable output.
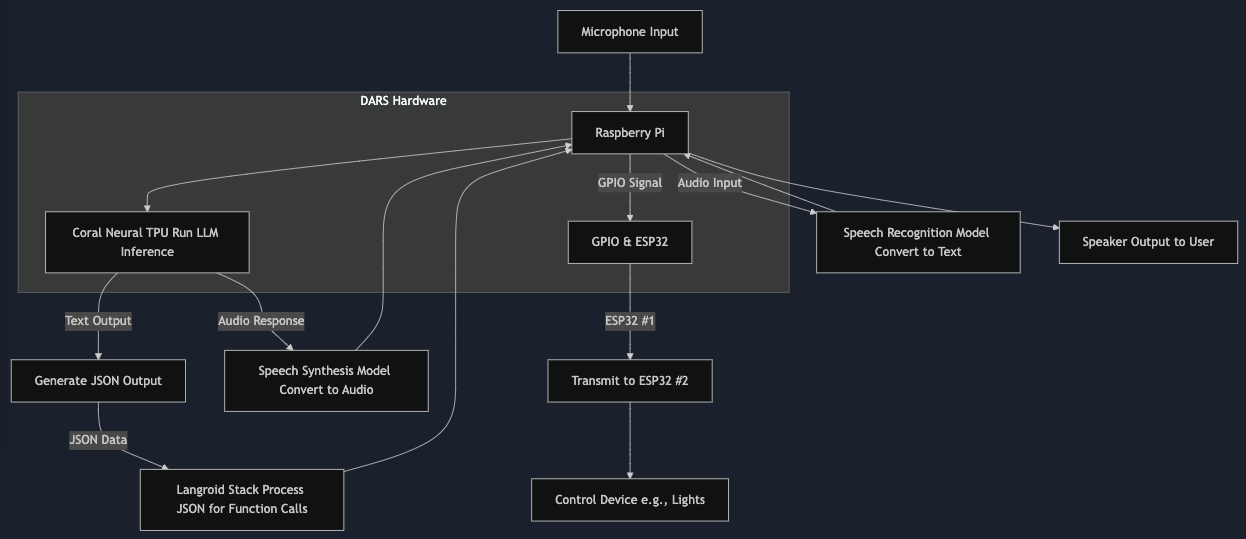
This diagram shows the flow of data through the system, and how the various components interact with each other. The system will be able to take in audio input, convert that to text, run the text through the language model, and then generate a JSON output. This JSON output will then be processed by the Langroid stack, which will determine what function calls need to be made. The system will then be able to control devices such as lights, and output audio to the user.
While this diagram is quite complex, it is necessary for the system to function as intended, as we want to create this project using minimal online SAAS services for the models, and instead run them locally.
External Components
ESP32: One important decision was the choice of ESP32 for the GPIO interface. We wanted a wireless solution for dormitories, and ESP32’s are a great option for a variety of reasons. They are cheap, have a low power consumption, and can be programmed using the Arduino IDE. This makes them a great choice for this project. And consider that their main use will be to control lights and other devices, their low power consumption is a great advantage.
Coral Neural TPU: The Coral Neural TPU is another important component of this project. We knew that there was no way that the raspberry pi 5 would be able to run the language model on its own without using online services, so we needed a way to run the model locally. The Coral Neural TPU is a great option for this, as it is specifically designed to run large language models. This will allow us to run the language model locally, without needing to rely on cloud services.
Chassis Design
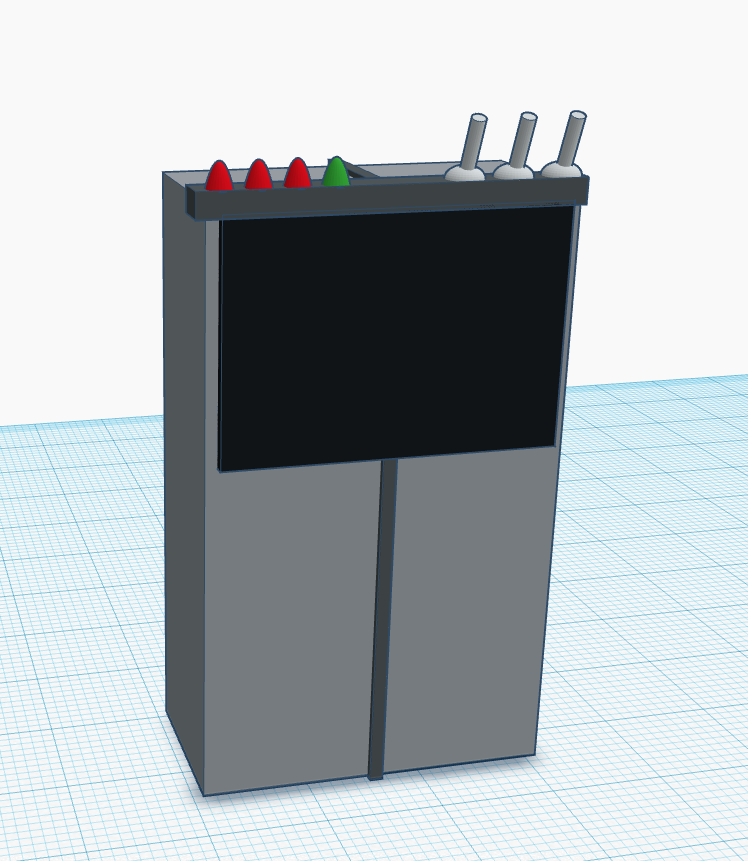
For the chassis, we want to create something that looks similar in appearance to TARS, but we do not have the robotics expertise to make it functional. The Black block will server as a small screen to debug and provide further insight into what the system is doing. The Lights on the top will represent options like if DARS is currently listening, if a certain setting is enabled, and what it is currently thinking. This will also include some simple switches, to toggle listening and other options you need easy access to.
Our Rough Design
TARS from Interstellar, for comparison

While it doesn’t provide much, this chassis gives us a lot of space to fill with all the hardware we need to make this run, and also provides a nice aesthetic to the project.
Keep in mind, this is also a very rough sketch of the model. We are by no means experts in 3d modeling, and the look is far from the most difficult/important part of the begining stages of this project.
Software Design Choices
Language Model: We chose to use Ollama 3.1 for this project. This is because Ollama is an open source language model that is based on the GPT-3 architecture. Ollama is known for packing the best accuracy for its size, and it is also known for being easy to fine tune. This makes it a great choice for this project, as we will need to fine tune the model to understand human natural language, function calling, and to have a sense of humor.
Speech Synthesis: We will be using Coqui TTS for this project, as it is open source, lightweight, and supports voice cloning well enough to mimic the voice of TARS. This will allow us to generate audio output that sounds like TARS, which will be important for the project.
Speech Recognition: We will be using DeepSpeech by Mozilla for this project, as it is open source, lightweight, and has a good accuracy rate. This will allow us to convert audio input to text, which will then be run through the language model.
Natural Language Framework: We will be using the Langroid stack for this project. This is a set of libraries that we have developed that will allow us to convert the output of the language model to function calls. This will allow us to control devices such as lights, and output audio to the user.
Budget
(including materials and labor itemized as well as an
overall estimated project cost)
Our budget for this project is as follows:
| Item | Cost | Quantity | Total |
|---|---|---|---|
| Nvidia A100 Rental | $200 | 1 | $200 |
| Raspberry Pi 5 | $100 | 1 | $100 |
| Coral Neural TPU | $150 | 1 | $150 |
| ESP32 | $5 | 5 | $25 |
| Chasis materials | $30 | 1 | $30 |
| Microphone | $10 | 1 | $10 |
| Speaker | $10 | 1 | $10 |
| Small Screen | $20 | 1 | $20 |
| Misc Pi Components | $20 | 1 | $20 |
By far the most expensive part of this project is the Nvidia A100 rental. This is necessary for the project to be a success, as the model is too large to fit on the raspberry pi 5. The other components are relatively cheap, but they are still necessary for the project to function as intended. Luckily, since the model we are working with is only 8B parameters, we won’t need to train it for too long.
Another big expense is the Coral Neural TPU. This is necessary for the project to run the language model locally, without needing to rely on cloud services. The other components are relatively cheap, but they are still necessary for the project to function as intended.
In addition, we also needed to purchase a Raspberry Pi 5 over the Pi 4 that we have been using in class. We decided this because we not only needed the hardware upgrades from the Pi 5, but the bleeding edge software stack we are using requires more modern systems that are better supported.
While labor is a concern on this project, it is entirely a solo undertaking, so we do not need to worry about labor costs.
Project Plan
Our timescale is designed to give us enough time to figure out the software challenges in the beginning, as that is by far the most difficult undertaking of this project.
Once we have the hardware side of things complete, there is not much else to improve there besides vanity design choices. But the models behind the project will never be completely perfect, and thus, will always be able to be improved.
Gantt Chart:

This Gantt chart gives us a rough estimation of our timeline for the project. There is a lot of empty space, but that it because of how unpredictable the troubleshooting in this field can be. The model training may end up being the easiest part, or we could reach a block that could hold us back weeks.
The chart also puts a heavy emphasis on getting the wireless systems to work. While this may not seem like it would take that long, we also need to develop a reliable system to control the power to certain devices, and in some cases, do more than that(like controlling the specific color of a light).
For this reason, we chose the esp32, as it has a lot of onboard processing power built in. So in cases where we need to do more than just manage power, we can bake that into the esp32, and the language model would only have to supply something like a RGB code.
Fallback Plan
If we are unable to train the model on the Nvidia A100, or we fall behind/realize we cant complete the project, the essential idea is still pretty much the same, except on how we would be running the inference. While I really don’t want to, the option of using OpenAI API and other software as a service options is still available to us.
This would work very well, as OpenAI has a really strong function calling system built in. This would allow us to skip the Langroid stack, and instead just use the OpenAI API to control devices. This would be a last resort, but it is a possibility.
Target Market
While this project itself is mainly geared towards people like me, who enjoy these sorts of techie devices, the market that this kind of technology is aimed at has a huge potential. The ability for Modern Transformers to be able to understand and replicate natural language gives them a huge advantage in the automated home industry.
Up until this point, voice assistants have been… well… pretty much useless. Yes, you could ask it to play a song or send a text, but anything more complicated or uniquely phrased, they had no idea how to handle.
This project paves the way for a real home assistant that can bridge the gap between human language and the devices in our living areas that we want to control. Translating from natural language to a discrete output is an untapped market with a huge potential to create the virtual assistants we all dreamed of. And with the open source nature of the project, it is easy to see how this could be implemented in a wide variety of devices.
By building a system that successfully links human natural language to home control, we hope that process can be replicated to other factors of life, where human language is the most efficient way to interface with a system. Cases where advanced machines exists, but are not able to be controlled by a human, are where this technology will shine, as it can make any system more user friendly.
We hope to bring the dream of virtual assistants from movies like Iron Man and Interstellar to reality, and make them accessible to everyone in a way that we all hoped that Siri and Alexa would be.
References
- mozilla. (2019, December 13). mozilla/DeepSpeech. GitHub. https://github.com/mozilla/DeepSpeech
For speech recodnition, deepspeech is a great choice. It is open source, lightweight, and has a good accuracy rate. This will allow us to convert audio input to text, which will then be run through the language model.
- langroid. (2023). GitHub - langroid/langroid: Harness LLMs with Multi-Agent Programming. GitHub. https://github.com/langroid/langroid
For the language model frameework and function calling, Langroid provides all the tools we need and some very usefull LLM manipulation methods.
- Eren, G., & The Coqui TTS Team. (2021, January 1). Coqui TTS. GitHub. https://github.com/coqui-ai/TTS
For speech synthesis, Coqui TTS gives us voice cloning and strong voice replication in a lightweight open source package.
- unslothai/unsloth. (2024, January 12). GitHub. https://github.com/unslothai/unsloth
For fine tuning the ollama language models, provides some tooling to do it much more efficiently.